
Introduction
When working with large datasets in industries such as finance or HR, it’s common to need to find specific records, like the nth highest salary among employees. In this blog post, we will explore how to achieve this using PySpark, a powerful tool for distributed data processing.
Understanding the Problem
Finding the Nth highest salary may seem simple at first, but it becomes complex when dealing with large datasets and distributed systems. The problem requires sorting the data and then selecting the Nth element, which can be computationally intensive in a large dataset. PySpark provides efficient ways to solve this problem.
Why Use PySpark for This Task
PySpark, the Python API for Apache Spark, is designed for handling large-scale data processing. It’s particularly useful for tasks like finding the Nth highest salary because it can handle data spread across many nodes in a cluster. This makes the process faster and more scalable compared to traditional SQL queries on a single machine.
Code to Find the Nth Highest Salary in PySpark
Step 1: Setting Up PySpark
To begin, you need to set up PySpark on your local machine or a cloud environment. Install it using pip:
pip install pyspark
Once installed, you can start a PySpark session:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName(“NthHighestSalary”).getOrCreate()
Step 2: Creating a Sample DataFrame
Create a DataFrame to simulate employee salary data:

columns = [“EmpName”, “Salary”]
df = spark.createDataFrame(data, columns)
df.show()
This will provide you with a DataFrame that appears as follows:
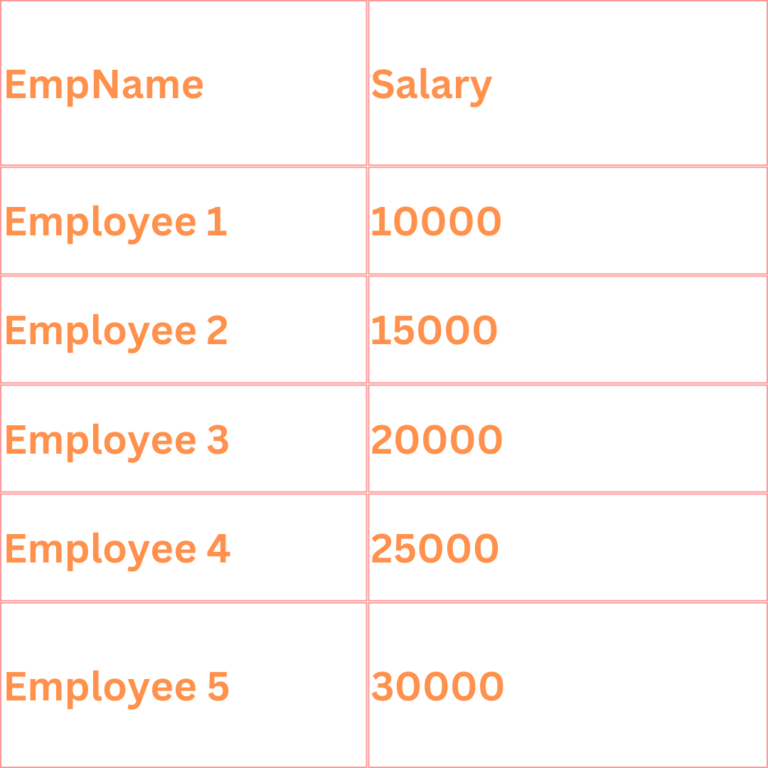
Step 3: Method 1 - Using Window Functions
One of the most efficient ways to find the Nth highest salary in PySpark is by using Window functions. Here’s how:
from pyspark.sql.window import Window
from pyspark.sql.functions import col, row_number
windowSpec = Window.orderBy(col(“Salary”).desc())
df = df.withColumn(“rank”, row_number().over(windowSpec))
nth_highest_salary = df.filter(col(“rank”) == N).select(“Salary”).collect()[0][0]
print(f”The {N}th highest salary is: {nth_highest_salary}”)
This method ranks the salaries and then selects the one corresponding to the Nth position.
Practical Example with Code
Let’s say you want to find the 3rd highest salary. Using the methods above, you can easily adjust the code to find:
N = 3
nth_highest_salary = df.filter(col(“rank”) == N).select(“Salary”).collect()[0][0]
print(f”The {N}th highest salary is: {nth_highest_salary}”)
This will output: The 3rd highest salary is: 20000.
Typical Mistakes and How to Prevent Them
- Large Data Volumes: Ensure your cluster has enough resources to handle large datasets.
- Handling Duplicates: If two employees have the same salary, the ranking might need to account for ties.
- Performance Tuning: Consider using cache or persist methods to speed up repeated operations.
FAQs Related to PySpark/Spark
What is the Nth Highest Salary in PySpark?
The Nth highest salary is the salary value at position N when the salaries are sorted in descending order. PySpark efficiently handles this task even for large datasets.
Why is PySpark Preferred for Big Data Operations?
PySpark is preferred because it can process data in parallel across a cluster, making it much faster than processing on a single machine, especially for large datasets.
How Does the Window Function Work in PySpark?
Window functions allow operations like ranking and aggregating across partitions. They’re crucial for tasks like finding the Nth highest salary as they efficiently handle the sorting and selection.